LA BIOSYNTHESE DES
PROTEINES
1)
Introduction :
Les organismes vivants synthétisent des protéines qui sont des macromolécules
constituées d’un enchaînement d’amino-acides. Il est intéressant de savoir
comment les unités amino-acides sont amenées à se lier en séquences précises,
spécifiques à chaque type de protéine. D’une façon annexe, il est intéressant
de savoir, aussi, comment l’information sur la séquence d’enchaînement des
amino-acides se transmet à chaque génération de cellules.
Il est à présent établi que des
molécules géantes de désoxyribonucléoprotéines, qui sont des acides désoxyribonucléiques (ADN) liés à
des protéines de soutien, sont responsables du contrôle génétique ; elles
sont essentiellement situées dans les noyaux des cellules et sont appelées
chromosomes (du grec khrôma :
couleur et sôma : corps) ;
on en trouve aussi dans les mitochondries (organites responsables de la
production d’énergie pour les cellules et transmises exclusivement par les
femelles) ; on sait aussi, plus précisément que la fraction protéique de
ces molécules n’est pour rien dans les informations génétiques nécessaires à la
biosynthèse des enzymes et autres protéines, c’est l’ADN qui porte toutes ces
informations ; c’est donc sur la structure de l’ADN qu’il faut à présent
se pencher.
2)
La structure de l’ADN :
L’ADN varie d’un individu à un autre et
d’une espèce à une autre dans la nature ; il y a donc autant d’ADN que
d’individus, d’espèces, etc.. donc de groupes taxinomiques. Il peut paraître
étrange dans ces conditions de parler de structure de l’ADN ; il faut
cependant savoir qu’on peut dégager une structure de base commune à toutes les
molécules d’ADN et c’est cette structure que l’on va examiner.
Les molécules d’ADN sont très grosses (ordre
de grandeur de leur masse molaire : entre 1.106 et 4.109 daltons (ou g.mol-1)) et peuvent
être photographiées au microscope électronique. La diffraction des rayons
X montre que l’ADN est constitué de deux
longues chaînes moléculaires entrelacées qui forment une hélice à deux brins
d’environ 2nm de diamètre. Les deux brins sont fermement accrochés l’un à
l’autre ; ils sont composés d’éléments permettant l’établissement de
liaisons hydrogène solides, entre eux ; ce fait est confirmé par les
expériences suivantes : si l’ADN est chauffé vers 80°C, dans certaines
conditions, les brins de l’hélice se séparent en deux fragments
indépendants ;

si
ensuite on refroidit lentement la matière, dans
certaines conditions, les deux fragments se recombinent et régénèrent la
structure en hélice.
Des études chimiques, montrent que les brins d’ADN ont la
structure d’une longue chaîne de polymère faite d’une alternance d’éléments
phosphate et d’éléments glucidiques substitués par une base azotée :
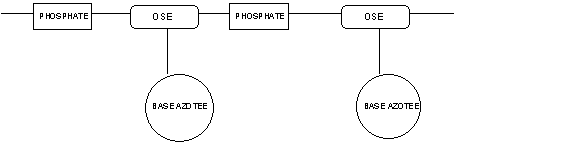
L’élément
glucidique (ose) est le (D)-2-désoxyribose :
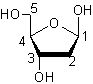
Il
est lié à deux groupes phosphate par des fonctions ester impliquant les groupes
hydroxyles en 3 et 5. Le motif de l’épine dorsale de l’ADN peut de ce fait être
vue comme un ester phosphorique d’un 1,3 glycol :
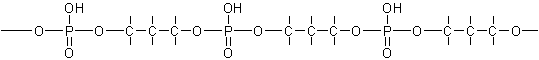
En
y incluant les cycles du désoxyribose on arrive à une structure plus
détaillée :
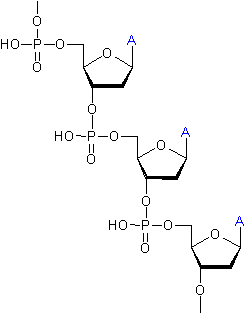
Chaque
fragment glucidique de l’ADN est relié en position 1’ à une des quatre bases
azotées, adénine, guanine, cytosine et thymine, notées A et dont on donne
ci-dessous la structure, par une liaison N-glycosidique. Les quatre bases sont
des dérivés soit de la pyrimidine, soit de la purine.
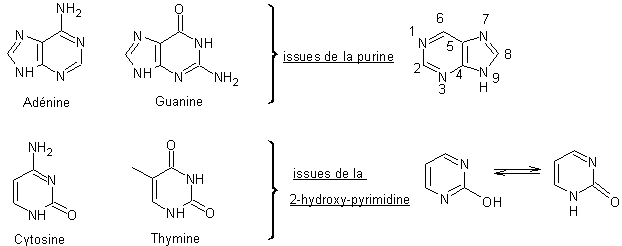
Remarque :
Quand
l’ose est lié à une base azotée on numérote 1,2,3,4….les atomes de cette base
et 1’, 2’, 3’ , ….les atomes du fragment glucidique.
Avec
l’adénine, la liaison N-glycosidique qui s’établit, selon l’équation
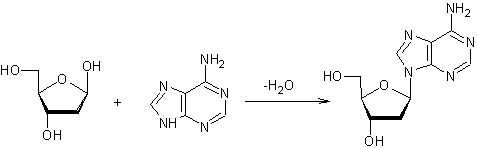
conduit
toujours au β-N-désoxyribofuranoside.
L’estérification
du groupe hydroxyle placé en 5’ des désoxyribose nucléosides avec l’acide
phosphorique conduit aux nucléotides correspondants. Ainsi avec
l’adénine on aboutit à l’adénine désoxyribonucléotide.
L’ADN
peut être considéré comme un édifice construit à partir des nucléotides,
constituant des blocs monomères, par estérification du groupe hydroxyle placé
en 3’ par le groupe phosphate d’un autre nucléotide.
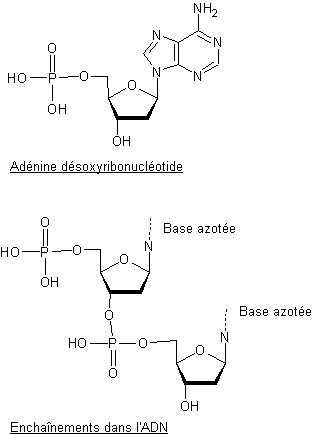
Le
nombre d’unités nucléotides dans une chaîne d’ADN varie d’environ 3000 à 107.
Un
fait surprenant constaté dès 1953 par Watson et Crick (tous deux Prix Nobel de
médecine en 1962) est que dans les différents ADN que l’on peut rencontrer, le
rapport Adénine/Thymine ainsi que le rapport Guanine/Cytosine vaut toujours un
pour un et ceci quel que soit le nombre d’Adénine et de thymine que l’ADN peut
avoir ; ce qui leur fit conclure que les liaisons hydrogène qui existent
entre les deux brins de l’hélice se font toujours entre l’adénine d’un brin et
la thymine de l’autre brin ou bien entre la guanine d’un brin et la cytosine de
l’autre brin. Les deux brins sont ainsi complémentaires au regard des bases
azotées qu’ils contiennent. Si par exemple pour un brin la séquence des bases
azotées est la suivante (A pour adénine, C pour Cytosine, T pour Thymine,
G pour Guanine) :
![]()
Celle
de l’autre brin en vis-à-vis est :
![]()
Les
deux brins de l’hélice se situent donc ainsi l’un par rapport à l’autre :
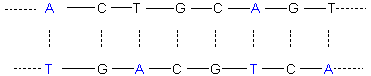

Il
y a 10 paires de bases pour une rotation de 360° de la chaîne ; le pas géométrique
de l’hélice est de 3,4 nm.
On
peut voir sur les deux représentations ci-dessous comment se font les liaisons
hydrogène entre guanine et cytosine d’une part et entre adénine et thymine
d’autre part :
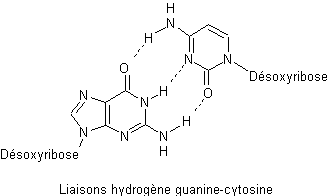
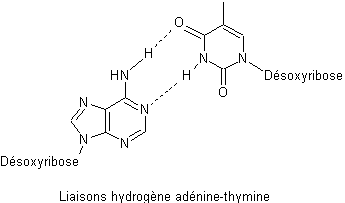
On
remarque qu’entre guanine et cytosine il y a trois liaisons hydrogène alors
qu’il n’y en a que deux entre adénine et thymine.
3)
La réplication de l’ADN :
L’ADN
renferme la « recette » génétique qui fait que la division cellulaire
produit des cellules identiques. En se reproduisant lui-même, il perpétue
l’information nécessaire à la régulation de la synthèse d’enzymes spécifiques et
d’autres protéines de la structure cellulaire.
L’information
génétique que contient l’ADN dépend de l’arrangement des bases symbolisées par
A,T,G et C le long de l’épine dorsale phosphate-élément glucidique,
c’est-à-dire de l’arrangement des 4 nucléotides spécifiques à l’ADN. Ainsi la
séquence G-A-C par exemple, à un endroit, correspond à un message différent de
celui qui correspond à A-G-C.
Par
action de l’acide nitreux, on peut chimiquement modifier les groupes amine
primaire de l’adénine de la cytosine et de la guanine et les transformer en
groupes OH et ceci aussi bien in vitro (en
dehors de la cellule) qu’ in vivo (dans
la cellule) ; ceci change totalement le message génétique, puisque l’ADN
ainsi modifié conduit à des mutations dans l’organisme dont il est issu.
L’ADN
se duplique de la manière suivante : les deux brins de la double hélice se
séparent partiellement et deviennent des matrices ; les enzymes se mettent
à assembler le nouvel ADN en couplant les nucléotides les uns aux autres de
façon complémentaire de ceux de la matrice c’est-à-dire en couplant adénine et
thymine, guanine et cytosine. On obtient finalement deux nouvelles doubles
hélices identiques à la double hélice de départ. Ce phénomène se produit lors
de la mitose qui donne deux cellules identiques sans recombinaison ou bien lors
de la méiose qui conduira à produire des cellules haploïdes que sont les
gamètes mâles ou femelles (le germen) avec recombinaison de l’ADN.
4)
Le rôle de l’ARN :
Il est difficile d’assigner un rôle direct à
l’ADN dans la synthèse des protéines dans la mesure où la plupart des synthèses
des protéines ont lieu en dehors du noyau c'est-à-dire dans des zones de la
cellule qui ne contiennent pas d’ADN. C’est à l’ ARN (Acide ribonucléique) qu’est dévolu le rôle
de transmettre le code génétique dans les zones où ont lieu les synthèses des
protéines.
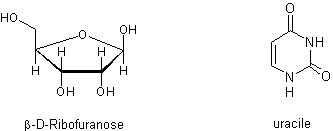
C’est
l’ADN qui donne naissance à l’ARN dans le noyau des cellules selon un mode de
duplication semblable à celui donné plus haut pour l’ADN. L’ARN est constitué
de chaînes beaucoup plus courtes que l’ADN, et diffère de celui-ci par la
nature du fragment glucidique (le ribose au lieu du désoxyribose) et par le
fait que la thymine est remplacée par l’uracile.
Dés
que sa synthèse est faite, l’ARN se détache de la matrice et rejoint les zones
où ont lieu les synthèses des protéines ; il va apporter le code suivant
lequel ces synthèses devront avoir lieu, on l’appelle l’ARN messager ou mARN.
Le
rôle précis de ce mARN est d’indiquer l’ordre suivant lequel les acides aminés
vont s’enchaîner ; en effet à chaque séquence de trois bases qui le
constituent (et que l’on appelle un codon), correspond un acide aminé. Ainsi au
codon G C A correspond l’alanine, au codon G G A la glycine ….
Le
nombre de possibilités qui résultent du groupement des quatre bases trois par
trois est de 64 (43) ; cela veut dire qu’il y a 64 séquences
possibles ; or il n’y a que 20 acides aminés participant à la synthèse des
protéines. Cela veut dire qu’il y a plusieurs codons pour chaque acide aminé,
sauf pour deux d’entre eux, le tryptophane
et la méthionine pour lesquels il n’y en
a qu’un.
Mention
particulière pour le codon A U G, il peut induire le démarrage de la synthèse
d’une chaîne polypeptidique, mais il peut aussi s’il apparaît dans une chaîne
déjà en construction programmer la méthionine. Trois des soixante quatre codons
sont exclusivement réservés à l’arrêt de la croissance de la chaîne ; ce
sont les codons U G A, U A A, U A G.
Environ 85% de l’ARN d’une cellule est
localisé dans le cytoplasme en paquets étroitement associés à des protéines.
Ces ribonucléoprotéines sont appelées ribosomes et constituent le lieu où sont
synthétisées la plupart des protéines de la cellule ; en plus du mARN il
existe des tARN dont le rôle est de transporter un acide aminé particulier (à
un tARN correspond un acide aminé) lorsque la matrice mARN le demande, dans la
chaîne polypeptidique en formation, Les tARN
ou ARN de transport, sont des molécules de faible masse molaire, ne
contenant que 70 à 90 nucléotides environ.
Tableau
des codons qui interviennent dans la synthèse des protéines :
|
Acide aminé |
Codons correspondants |
Acide aminé |
Codons correspondants |
Acide aminé |
Codons correspondants |
|
Alanine (Ala) |
GCA GCC GCG GCU |
Histidine (His) |
CAC CAU |
Sérine (Sér) |
AGC AGU UCA UCG UCC UCU |
|
Arginine (Arg) |
AGA AGG CGA CGC CGG CGU |
Isoleucine (Ile) |
AUA AUC AUU |
Thréonine (Thr) |
ACA ACC ACG ACU |
|
Asparagine (Asn) |
AAC AAU |
Leucine (Leu) |
CUA CUC CUG CUU UUA UUG |
Tryptophane (Trp) |
UGG |
|
Acide aspartique (Asp) |
GAC GAU |
Lysine (Lys) |
AAA AAG |
Tyrosine (Tyr) |
UAC UAU |
|
Cystéine (Cys) |
UGC UGU |
Méthionine (Mét) |
AUG |
Valine (Val) |
GUA GUG GUC GUU |
|
Glutamine (Gln) |
CAA CAG |
Phénylalanine (Phé) |
UUU UUC |
Initiation de la chaîne |
AUG |
|
Acide glutamique (Glu) |
GAA GAG |
Proline (Pro) |
CCA CCC CCG CCU |
Fin de la chaîne |
UGA UAA UAG |
|
Glycine (Gly) |
GGA GGC GGG GGU |
|
|
|
|
Remarques :
a) La séquence
complète des bases azotées de l’ADN constitue son code génétique.
b) Sous l’effet d’une radiation, d’un produit
chimique ou d’une erreur de réplication (bien que des mécanismes
d’auto-vérification performants existent)
des mutations peuvent se produire dans la séquence des bases de l’ADN. Cela
peut consister par exemple à remplacer une base par une autre. Comme à la
plupart des acides aminés correspondent plusieurs codons il se peut que la
mutation ne modifie pas la séquence d’acide aminés dans la protéine
synthétisée ; par exemple, si par mutation de l’ADN on a une séquence CCC
ou CCG ou CCU qui vient remplacer la séquence CCA initiale, cela ne modifiera
pas la protéine synthétisée puisque dans tous les cas ce sera une molécule de
proline qui viendra s’insérer dans la chaîne poplypeptidique en formation. On
voit là l’intérêt de l’existence de plusieurs codons pour un même acide aminé.